Git和SVN之间的区别:
==GIT是分布式的,SVN不是:== 最重要的区别
这是Git和其他非分布式版本控制系统(如:SVN、CVS)最核心的区别。
Git和SVN一样有自己的集中式版本库或服务器。但是Git更倾向于分布式模式,也就是每个开发人员从中心版本库/服务器checkout代码后会在自己的机器上克隆一个自己的版本库。可以说如果你被困在一个不能联网的地方时,仍然可以提交文件,查看==历史版本记录==,创建项目分支等。。
同样,这种分布式的操作模式对于开源软件社区的开发来说也是巨大的恩赐,不用再像以前那样做出补丁包,通过email方式发出,只需要创建分支,向团队发除一个推请求。这样能让自己的代码保持最新,并且不会在传输过程中丢失。(如:GitHub)
- ==SVN(Subversion)是集中式管理的版本控制器,而Git是分布式管理的版本控制器==!这是两者之间最核心的区别。 SVN只有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。 Git每一个终端都是一个仓库,客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。每一次的提取操作,实际上都是一次对代码仓库的完整备份。Git不仅仅是个版本控制系统,它也是个内容管理系统(CMS),工作管理系统等。如果你是一个具有使用SVN背景的人,你需要做一定的思想转换,来适应Git提供的一些概念和特征。
Git把内容按元数据方式存储,而SVN是按文件。
- 所有的资源控制系统都是把文件的元信息隐藏在类似于.svn等的文件夹中。.git目录的体积跟.SVN比较,会发现他们的差距很大。因为.git目录是处于你的机器的上的一个克隆版本的版本库,它拥有中心版本库上所有的东西,如:标签、分支、版本记录等。
Git分支与SVN的分支不同。
分支在SVN中一点不特别,就是版本库中的另外的一个目录。如果你想知道是否合并了一个分支,你需要手工运行像这样的命令svn propget svn:mergeinfo,来确认代码是否被合并。感谢Ben同学指出这个特征。所以,经常会发生有些分支被遗漏的情况。
然而,处理GIT的分支却是相当的简单和有趣。你可以从同一个工作目录下快速的在几个分支间切换。你很容易发现未被合并的分支,你能简单而快捷的合并这些文件。
GIT没有一个全局的版本号,而SVN有: 目前为止这是跟SVN相比GIT缺少的最大的一个特征。你也知道,SVN的版本号实际是任何一个相应时间的源代码快照。我认为它是从CVS进化到SVN的最大的一个突破。因为GIT和SVN从概念上就不同,我不知道GIT里是什么特征与之对应。如果你有任何的线索,请在评论里奉献出来与大家共享。
更新:有些读者指出,我们可以使用GIT的SHA-1来唯一的标识一个代码快照。这个并不能完全的代替SVN里容易阅读的数字版本号。但,用途应该是相同的。
GIT的内容完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
SVN和Git对比梳理
在日常运维工作中,经常会用到版本控制系统,目前用到最广泛的版本控制器就是SVN和Git,那么这两者之间有什么不同之处呢? SVN(Subversion)是集中式管理的版本控制器,而Git是分布式管理的版本控制器!这是两者之间最核心的区别。 SVN只有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。 Git每一个终端都是一个仓库,客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。每一次的提取操作,实际上都是一次对代码仓库的完整备份。Git不仅仅是个版本控制系统,它也是个内容管理系统(CMS),工作管理系统等。如果你是一个具有使用SVN背景的人,你需要做一定的思想转换,来适应Git提供的一些概念和特征。
---------------------------------------------------------------------------------------------------
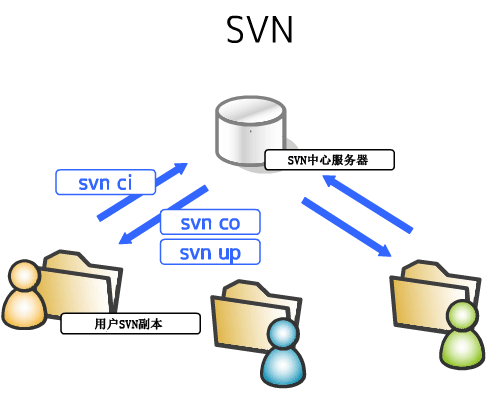
集中式版本控制系统: 版本库是集中存放在中央服务器的,而干活的时候,用的都是自己的电脑,所以要先从中央服务器取得最新的版本,然后开始干活,干完活了,再把自己的活推送给中央服务器。中央服务器就好比是一个图书馆,你要改一本书,必须先从图书馆借出来,然后回到家自己改,改完了,再放回图书馆。
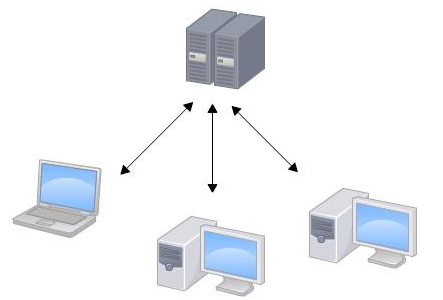
集中式版本控制系统最大的毛病就是必须联网才能工作,如果在局域网内还好,带宽够大,速度够快,可如果在互联网上,遇到网速慢的话,可能提交一个10M的文件就需要5分钟,这还不得把人给憋死啊。
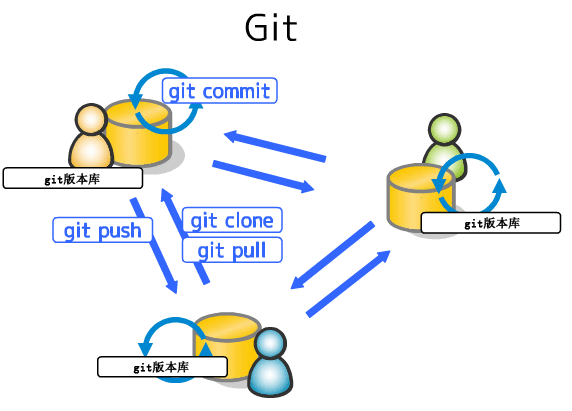
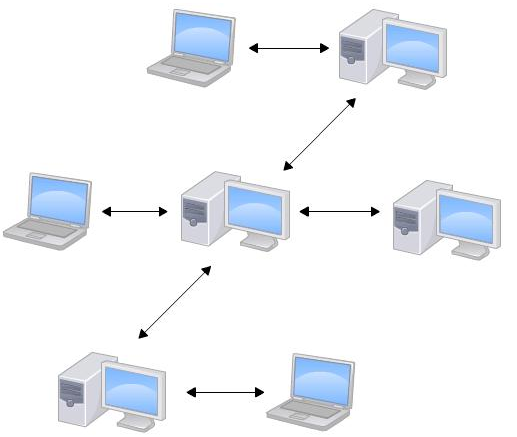
分布式版本控制系统: 首先,分布式版本控制系统根本没有“中央服务器”,每个人的电脑上都是一个完整的版本库,这样,你工作的时候,就不需要联网了,因为版本库就在你自己的电脑上。既然每个人电脑上都有一个完整的版本库,那多个人如何协作呢?比方说你在自己电脑上改了文件A,你的同事也在他的电脑上改了文件A,这时,你们俩之间只需把各自的修改推送给对方,就可以互相看到对方的修改了。
和集中式版本控制系统相比,分布式版本控制系统的安全性要高很多,因为每个人电脑里都有完整的版本库,某一个人的电脑坏掉了不要紧,随便从其他人那里复制一个就可以了。而集中式版本控制系统的中央服务器要是出了问题,所有人都没法干活了。
在实际使用分布式版本控制系统的时候,其实很少在两人之间的电脑上推送版本库的修改,因为可能你们俩不在一个局域网内,两台电脑互相访问不了,也可能今天你的同事病了,他的电脑压根没有开机。因此,分布式版本控制系统通常也有一台充当“中央服务器”的电脑,但这个服务器的作用仅仅是用来方便“交换”大家的修改,没有它大家也一样干活,只是交换修改不方便而已。
当然,Git的优势不单是不必联网这么简单,后面我们还会看到Git极其强大的分支管理,把SVN等远远抛在了后面。
那么Git和SVN两者之间具体有哪些不同?下面详细做下对比:
一、搞清楚两种模式:集中式VS分布式 (1)SVN属于集中式的版本控制系统 集中式的版本控制系统都有一个单一的集中管理的服务器,保存所有文件的修订版本,而协同工作的人们都通过客户端连到这台服务器,取出最新的文件或者提交更新。
SVN的特点概括起来主要由以下几条: 1)每个版本库有唯一的URL(官方地址),每个用户都从这个地址获取代码和数据; 2)获取代码的更新,也只能连接到这个唯一的版本库,同步以取得最新数据; 3)提交必须有网络连接(非本地版本库); 4)提交需要授权,如果没有写权限,提交会失败; 5)提交并非每次都能够成功。如果有其他人先于你提交,会提示“改动基于过时的版本,先更新再提交”… 诸如此类; 6)冲突解决是一个提交速度的竞赛:手快者,先提交,平安无事;手慢者,后提交,可能遇到麻烦的冲突解决。
好处:每个人都可以一定程度上看到项目中的其他人正在做些什么。而管理员也可以轻松掌控每个开发者的权限。 缺点:中央服务器的单点故障。 若是宕机一小时,那么在这一小时内,谁都无法提交更新、还原、对比等,也就无法协同工作。如果中央服务器的磁盘发生故障,并且没做过备份或者备份得不够及时的话,还会有丢失数据的风险。最坏的情况是彻底丢失整个项目的所有历史更改记录,被客户端提取出来的某些快照数据除外,但这样的话依然是个问题,你不能保证所有的数据都已经有人提取出来。
简单来说,==SVN原理上只关心文件内容的具体差异。每次记录有哪些文件作了更新,以及都更新了哪些行的什么内容。==
(2)Git属于分布式的版本控制系统 Git记录版本历史只关心文件数据的整体是否发生变化。Git 不保存文件内容前后变化的差异数据。 实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一连接。
在分布式版本控制系统中,客户端并不只提取最新版本的文件快照,而是把原始的代码仓库完整地镜像下来。这么一来,任何一处协同工作用的服务器发生故障,事后都可以用任何一个镜像出来的本地仓库恢复。这类系统都可以指定和若干不同的远端代码仓库进行交互。籍此,你就可以在同一个项目中,分别和不同工作小组的人相互协作。你可以根据需要设定不同的协作流程。
另外,因为Git在本地磁盘上就保存着所有有关当前项目的历史更新,并且Git中的绝大多数操作都只需要访问本地文件和资源,不用连网,所以处理起来速度飞快。用SVN的话,没有网络或者断开VPN你就无法做任何事情。但用Git的话,就算你在飞机或者火车上,都可以非常愉快地频繁提交更新,等到了有网络的时候再上传到远程的镜像仓库。换作其他版本控制系统,这么做几乎不可能,抑或是非常麻烦。
Git特点: 1)Git中每个克隆(clone)的版本库都是平等的。你可以从任何一个版本库的克隆来创建属于你自己的版本库,同时你的版本库也可以作为源提供给他人,只要你愿意。 2)Git的每一次提取操作,实际上都是一次对代码仓库的完整备份。 3)提交完全在本地完成,无须别人给你授权,你的版本库你作主,并且提交总是会成功。 4)甚至基于旧版本的改动也可以成功提交,提交会基于旧的版本创建一个新的分支。 5)Git的提交不会被打断,直到你的工作完全满意了,PUSH给他人或者他人PULL你的版本库,合并会发生在PULL和PUSH过程中,不能自动解决的冲突会提示您手工完成。 6)冲突解决不再像是SVN一样的提交竞赛,而是在需要的时候才进行合并和冲突解决。
除此之外: 1)Git也可以模拟集中式的工作模式 Git版本库统一放在服务器中 可以为 Git 版本库进行授权:谁能创建版本库,谁能向版本库PUSH,谁能够读取(克隆)版本库 团队的成员先将服务器的版本库克隆到本地;并经常的从服务器的版本库拉(PULL)最新的更新; 团队的成员将自己的改动推(PUSH)到服务器的版本库中,当其他人和版本库同步(PULL)时,会自动获取改变 2)Git 的集中式工作模式非常灵活 你完全可以在脱离Git服务器所在网络的情况下,如移动办公/出差时,照常使用代码库 你只需要在能够接入Git服务器所在网络时,PULL和PUSH即可完成和服务器同步以及提交 Git提供rebase 命令,可以让你的改动看起来是基于最新的代码实现的改动 3)Git有更多的工作模式可以选择,远非 Subversion能比的。
二、用法上理解 (1)Git是分布式的,而SVN不是分布而是集中式的,需要说明的是Git并不是目前唯一的分布式版本控制系统,还有比如Mercurial等,所以说它们差不许多。不过话说回来Git跟Svn一样有自己的集中式版本库和Server端,但Git更倾向于分布式开发,因为每一个开发人员的电脑上都有一个LocalRepository以即使没有网络也一样可以Commit,查看历史版本记录,创建项目分支等操作,等网络再次连接上Push到Server端。 从上面看GIt真的很棒,但是GIt adds Complexity,刚开始使用会有些疑惑,因为需要建两个Repositories(Local Repositories & Remote Repositories),指令很多,除此之外你需要知道哪些指令在Local Repository,哪些指令在Remote Repository。
(2)Git把内容按元数据方式存储,而SVN是按文件:因为git目录是处于你的机器上的一个克隆版的版本库,它拥有中心版本库上所有的东西,例如标签,分支,版本记录等。.git目录的体积大小跟.svn比较,你会发现它们差距很大。
(3)Git没有一个全局版本号,而SVN有:目前为止这是跟SVN相比Git缺少的最大的一个特征。
(4)Git的内容的完整性要优于SVN: GIT的内容存储使用的是SHA-1哈希算法。这能确保代码内容的完整性,确保在遇到磁盘故障和网络问题时降低对版本库的破坏。
(5)Git下载下来后,在OffLine状态下可以看到所有的Log,SVN不可以。
(6)刚开始用时很狗血的一点,SVN必须先Update才能Commit,忘记了合并时就会出现一些错误,git还是比较少的出现这种情况。 (7)克隆一份全新的目录以同样拥有五个分支来说,SVN是同时复製5个版本的文件,也就是说重复五次同样的动作。而Git只是获取文件的每个版本的 元素,然后只载入主要的分支(master)在我的经验,克隆一个拥有将近一万个提交(commit),五个分支,每个分支有大约1500个文件的 SVN,耗了将近一个小时!而Git只用了区区的1分钟!
(8)版本库(repository):SVN只能有一个指定中央版本库。当这个中央版本库有问题时,所有工作成员都一起瘫痪直到版本库维修完毕或者新的版本库设立完成。而 Git可以有无限个版本库。或者,更正确的说法,每一个Git都是一个版本库,区别是它们是否拥有活跃目录(Git Working Tree)。如果主要版本库(例如:置於GitHub的版本库)发生了什麼事,工作成员仍然可以在自己的本地版本库(local repository)提交,等待主要版本库恢复即可。工作成员也可以提交到其他的版本库!
(9)分支(Brach)不同。 分支在SVN中一点不特别,分支在SVN就是版本库中的另外一个完整目录,且这个目录拥有完整的实际文件。如果你想知道是否合并了一个分支,你需要手工运行像这样的命令svn propget svn:mergeinfo,来确认代码是否被合并。所以,经常会发生有些分支被遗漏的情况。如果工作成员想要开啟新的分支,那将会影响“全世界”!每个人都会拥有和你一样的分支。如果你的分支是用来进行破坏工作(安检测试),那将会像传染病一样,你改一个分支,还得让其他人重新切分支重新下载,十分狗血。而 Git,每个工作成员可以任意在自己的本地版本库开啟无限个分支。举例:当我想尝试破坏自己的程序(安检测试),并且想保留这些被修改的文件供日后使用, 我可以开一个分支,做我喜欢的事。完全不需担心妨碍其他工作成员。只要我不合并及提交到主要版本库,没有一个工作成员会被影响。等到我不需要这个分支时, 我只要把它从我的本地版本库删除即可。无痛无痒。
然而,处理GIT的分支却是相当的简单和有趣。你可以从同一个工作目录下快速的在几个分支间切换。你很容易发现未被合并的分支,你能简单而快捷的合并这些文件。Git的分支名是可以使用不同名字的。例如:我的本地分支名为OK,而在主要版本库的名字其实是master。最值得一提,我可以在Git的任意一个提交点(commit point)开启分支!(其中一个方法是使用gitk –all 可观察整个提交记录,然后在任意点开啟分支。)
(10)提交(Commit)上的不同:在SVN,当你提交你的完成品时,它将直接记录到中央版本库。当你发现你的完成品存在严重问题时,你已经无法阻止事情的发生了。如果网路中断,你根本没办法提交!而Git的提交完全属於本地版本库的活动。而你只需“推”(git push)到主要版本库即可。Git的“推”其实是在执行“同步”(Sync)。
最后总结一下: ==SVN的特点是简单,只是需要一个放代码的地方时用是OK的。== ==Git的特点版本控制可以不依赖网络做任何事情,对分支和合并有更好的支持==(这应该算是开发者最关心的地方)。
Git和SVN对待数据的方式
下面我们主要说一个关于 Git 其他版本管理系统的主要差别:对待数据的方式。
Git采用的是直接记录快照的方式,而非差异比较。我后面会详细介绍这两种方式的差别。
大部分版本控制系统(CVS、Subversion、Perforce、Bazaar 等等)都是以文件变更列表的方式存储信息,这类系统将它们保存的信息看作是一组基本文件和每个文件随时间逐步累积的差异。
具体原理如下图所示,理解起来其实很简单,每个我们对提交更新一个文件之后,系统记录都会记录这个文件做了哪些更新,以增量符号Δ(Delta)表示。
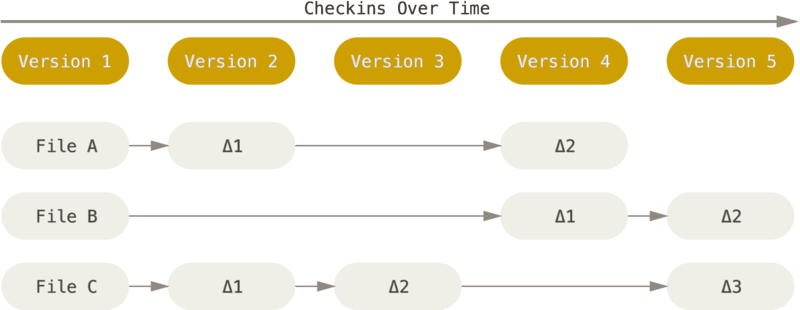
我们怎样才能得到一个文件的最终版本呢?
很简单,高中数学的基本知识,我们只需要将这些原文件和这些增加进行相加就行了。
这种方式有什么问题呢?
比如我们的增量特别特别多的话,如果我们要得到最终的文件是不是会耗费时间和性能。
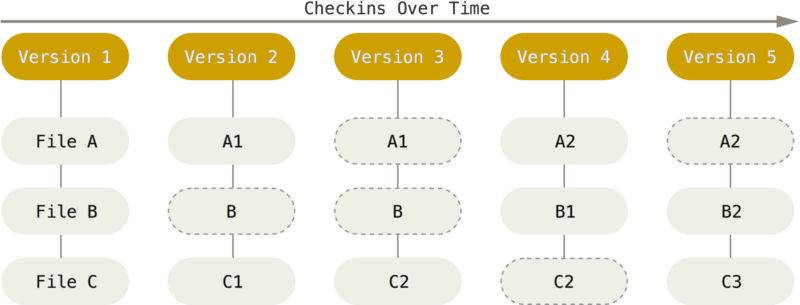
Git 不按照以上方式对待或保存数据。 反之,Git 更像是把数据看作是对小型文件系统的一组快照。 每次你提交更新,或在 Git 中保存项目状态时,它主要对当时的全部文件制作一个快照并保存这个快照的索引。 为了高效,如果文件没有修改,Git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。 Git 对待数据更像是一个 快照流。
Git 的三种状态
Git 有三种状态,你的文件可能处于其中之一:
- 已提交(committed):数据已经安全的保存在本地数据库中。
- 已修改(modified):已修改表示修改了文件,但还没保存到数据库中。
- 已暂存(staged):表示对一个已修改文件的当前版本做了标记,使之包含在下次提交的快照中。
由此引入 Git 项目的三个工作区域的概念:Git 仓库(.git directoty)、工作目录(Working Directory) 以及 暂存区域(Staging Area) 。
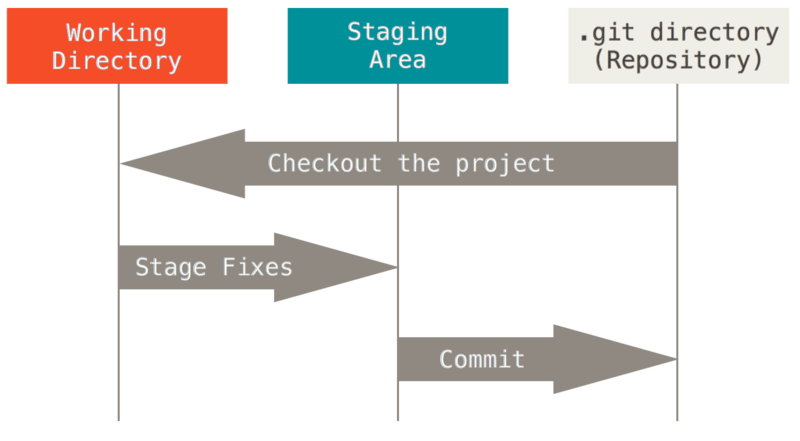
基本的 Git 工作流程如下:
- 在工作目录中修改文件。
- 暂存文件,将文件的快照放入暂存区域。
- 提交更新,找到暂存区域的文件,将快照永久性存储到 Git 仓库目录。
Git 使用快速入门
获取 Git 仓库
有两种取得 Git 项目仓库的方法。
- 在现有目录中初始化仓库: 进入项目目录运行
git init命令,该命令将创建一个名为.git的子目录。 - 从一个服务器克隆一个现有的 Git 仓库:
git clone [url]自定义本地仓库的名字:git clone [url]directoryname
记录每次更新到仓库
- 检测当前文件状态 :
git status - 提出更改(把它们添加到暂存区):
git add filename(针对特定文件)、git add *(所有文件)、git add *.txt(支持通配符,所有 .txt 文件) - 忽略文件:
.gitignore文件 - 提交更新:
git commit -m "代码提交信息"(每次准备提交前,先用git status看下,是不是都已暂存起来了, 然后再运行提交命令git commit) - 跳过使用暂存区域更新的方式 :
git commit -a -m "代码提交信息"。git commit加上-a选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过git add步骤。 - 移除文件 :
git rm filename(从暂存区域移除,然后提交。) - 对文件重命名 :
git mv README.md README(这个命令相当于mv README.md README、git rm README.md、git add README这三条命令的集合)
一个好的 Git 提交消息
一个好的 Git 提交消息如下:
标题行:用这一行来描述和解释你的这次提交
主体部分可以是很少的几行,来加入更多的细节来解释提交,最好是能给出一些相关的背景或者解释这个提交能修复和解决什么问题。
主体部分当然也可以有几段,但是一定要注意换行和句子不要太长。因为这样在使用 "git log" 的时候会有缩进比较好看。
提交的标题行描述应该尽量的清晰和尽量的一句话概括。这样就方便相关的 Git 日志查看工具显示和其他人的阅读。
推送改动到远程仓库
如果你还没有克隆现有仓库,并欲将你的仓库连接到某个远程服务器,你可以使用如下命令添加:·
git remote add origin,比如我们要让本地的一个仓库和 Github 上创建的一个仓库关联可以这样git remote add origin https://github.com/Snailclimb/test.git将这些改动提交到远端仓库:
git push origin master(可以把 master 换成你想要推送的任何分支)如此你就能够将你的改动推送到所添加的服务器上去了。
远程仓库的移除与重命名
- 将 test 重命名位 test1:
git remote rename test test1 - 移除远程仓库 test1:
git remote rm test1
查看提交历史
在提交了若干更新,又或者克隆了某个项目之后,你也许想回顾下提交历史。 完成这个任务最简单而又有效的工具是 git log 命令。git log 会按提交时间列出所有的更新,最近的更新排在最上面。
可以添加一些参数来查看自己希望看到的内容:
只看某个人的提交记录:
git log --author=bob
撤销操作
有时候我们提交完了才发现漏掉了几个文件没有添加,或者提交信息写错了。 此时,可以运行带有 --amend 选项的提交命令尝试重新提交:
git commit --amend
取消暂存的文件
git reset filename
撤消对文件的修改:
git checkout -- filename
假如你想丢弃你在本地的所有改动与提交,可以到服务器上获取最新的版本历史,并将你本地主分支指向它:
git fetch origin
git reset --hard origin/master
分支
分支是用来将特性开发绝缘开来的。在你创建仓库的时候,master 是“默认的”分支。在其他分支上进行开发,完成后再将它们合并到主分支上。
我们通常在开发新功能、修复一个紧急 bug 等等时候会选择创建分支。单分支开发好还是多分支开发好,还是要看具体场景来说。
创建一个名字叫做 test 的分支
git branch test
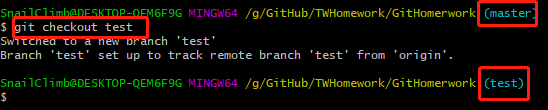
切换当前分支到 test(当你切换分支的时候,Git 会重置你的工作目录,使其看起来像回到了你在那个分支上最后一次提交的样子。 Git 会自动添加、删除、修改文件以确保此时你的工作目录和这个分支最后一次提交时的样子一模一样)
git checkout test
你也可以直接这样创建分支并切换过去(上面两条命令的合写)
git checkout -b feature_x
切换到主分支
git checkout master
合并分支(可能会有冲突)
git merge test
把新建的分支删掉
git branch -d feature_x
将分支推送到远端仓库(推送成功后其他人可见):
git push origin
推荐
在线演示学习工具:
「补充,来自issue729」Learn Git Branching https://oschina.gitee.io/learn-git-branching/ 。该网站可以方便的演示基本的git操作,讲解得明明白白。每一个基本命令的作用和结果。