线程CPU100%如何排查?
top -H -p
先通过top -H -p 找出CPU占用最大的几个 ,记录其Pid,然后将JVM日志输出 ,重启服务,减轻影响。
- 根据
进程pid&&线程id查看线程堆栈信息
jstack pid:查看指定进程中线程的堆栈信息,这个命令最终会打印出指定进程的线程堆栈信息,而实际线上情况发生时,我们应当把快速把堆栈信息输出到日志文本中,保留日志信息,然后迅速先重启服务,达到临时缓解服务器压力的目的。使用 jstack jstack 17499 > ./threadDump.log
一、引子
对于互联网公司,线上CPU飙升的问题很常见(例如某个活动开始,流量突然飙升时),按照本文的步骤排查,基本1分钟即可搞定!特此整理排查方法一篇,供大家参考讨论提高。
二、问题复现
线上系统突然运行缓慢,CPU飙升,甚至到100%,以及Full GC次数过多,接着就是各种报警:例如接口超时报警等。此时急需快速线上排查问题。
三、问题排查
不管什么问题,既然是CPU飙升,肯定是查一下耗CPU的线程,然后看看GC。
3.1 核心排查步骤
1.执行“top”命令:查看所有进程占系统CPU的排序。极大可能排第一个的就是咱们的java进程(COMMAND列)。PID那一列就是进程号。
2.执行“top -Hp 进程号”命令:查看java进程下的所有线程占CPU的情况。
3.执行“printf "%x\n 10"命令 :后续查看线程堆栈信息展示的都是十六进制,为了找到咱们的线程堆栈信息,咱们需要把线程号转成16进制。例如, printf "%x\n 10" -》打印:a,那么在jstack中线程号就是0xa.
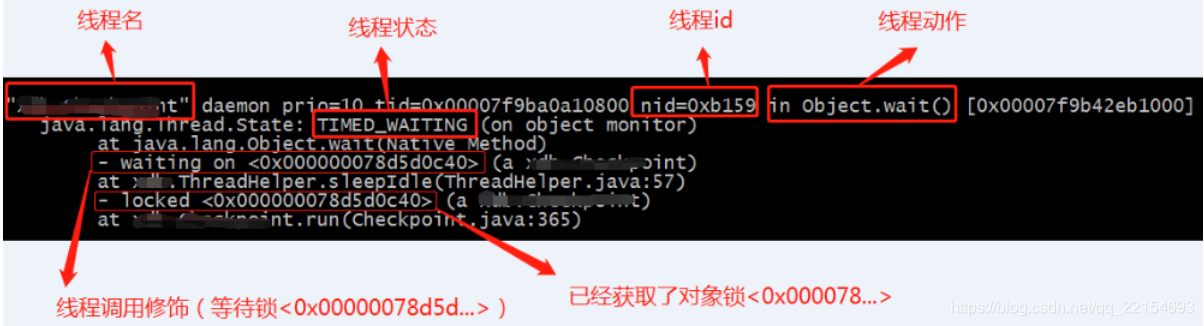
4.执行 “jstack 进程号 | grep 线程ID” 查找某进程下 -》线程ID(jstack堆栈信息中的nid)=0xa的线程堆栈信息。如果“"VM Thread" os_prio=0 tid=0x00007f871806e000 nid=0xa runnable”,第一个双引号圈起来的就是线程名,** 如果是“VM Thread”这就是虚拟机GC回收线程了 **
5.执行“jstat -gcutil 进程号 统计间隔毫秒 统计次数(缺省代表一致统计)”,查看某进程GC持续变化情况,如果发现返回中FGC很大且一直增大-》确认Full GC! 也可以使用“jmap -heap 进程ID”查看一下进程的堆内从是不是要溢出了,特别是老年代内从使用情况一般是达到阈值(具体看垃圾回收器和启动时配置的阈值)就会进程Full GC。
6.执行“jmap -dump:format=b,file=filename 进程ID”,导出某进程下内存heap输出到文件中。可以通过eclipse的mat工具查看内存中有哪些对象比较多。
3.2 原因分析
1.内存消耗过大,导致Full GC次数过多
执行步骤1-5:
- 多个线程的CPU都超过了100%,通过jstack命令可以看到这些线程主要是垃圾回收线程-》上一节步骤2
- 通过jstat命令监控GC情况,可以看到Full GC次数非常多,并且次数在不断增加。--》上一节步骤5
确定是Full GC,接下来找到具体原因:
- 生成大量的对象,导致内存溢出-》执行步骤6,查看具体内存对象占用情况。
- 内存占用不高,但是Full GC次数还是比较多,此时可能是代码中手动调用 System.gc()导致GC次数过多, 这可以通过添加 -XX:+DisableExplicitGC来禁用JVM对显示GC的响应。
2.代码中有大量消耗CPU的操作,导致CPU过高,系统运行缓慢;
执行步骤1-4:在步骤4 jstack,可直接定位到代码行。例如某些复杂算法,甚至算法BUG,无限循环递归等等。
3.由于锁使用不当,导致死锁。
执行步骤1-4: 如果有死锁,会直接提示。关键字:deadlock. 步骤四,会打印出业务死锁的位置。
造成死锁的原因:最典型的就是2个线程互相等待对方持有的锁。
4.随机出现大量线程访问接口缓慢。
代码某个位置有阻塞性的操作,导致该功能调用整体比较耗时,但出现是比较随机的;平时消耗的CPU不多,而且占用的内存也不高。
思路:
首先找到该接口,通过压测工具不断加大访问力度,大量线程将阻塞于该阻塞点。
执行步骤1-4:
"http-nio-8080-exec-4" #31 daemon prio=5 os_prio=31 tid=0x00007fd08d0fa000 nid=0x6403 waiting on condition [0x00007000033db000]
java.lang.Thread.State: TIMED_WAITING (sleeping)-》期限等待
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:340)
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:386)
at com.*.user.controller.UserController.detail(UserController.java:18)-》业务代码阻塞点
如上图,找到业务代码阻塞点,这里业务代码使用了TimeUnit.sleep()方法,使线程进入了TIMED_WAITING(期限等待)状态。
5.某个线程由于某种原因而进入WAITING状态,此时该功能整体不可用,但是无法复现;
执行步骤1-4:jstack多查询几次,每次间隔30秒,对比一直停留在parking 导致的WAITING状态的线程。例如CountDownLatch倒计时器,使得相关线程等待->AQS->LockSupport.park()。
"Thread-0" #11 prio=5 os_prio=31 tid=0x00007f9de08c7000 nid=0x5603 waiting on condition [0x0000700001f89000]
java.lang.Thread.State: WAITING (parking) ->无期限等待
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:304)
at com.*.SyncTask.lambda$main$0(SyncTask.java:8)-》业务代码阻塞点
at com.*.SyncTask$$Lambda$1/1791741888.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
线上问题排查:
业务日志 在系统出问题时,首先应该根据业务日志来排查问题。主要有grep、tail、more、less等命令。
数据库相关 假设出现Could not get JDBC Connection 、接口响应慢、线程打满等。 登录线上库,查看数据库连接情况:show processlist。查看当前数据库的连接情况。确实因为慢查询造成,须要手动kill。
JVM问题排查
一般通过下面几个工具都能定位出问题。
jps(JVM Process Status Tool)
查看Java进程的具体状态, 包括进程ID,进程启动的路径及启动参数等。
[root@izm5e4dhkm7u54kfwhgz9wz logs]# jps -mv
25481 Jps -mv -Dapplication.home=/usr/java/jdk1.8.0_151 -Xms8m
12489 medusa-server.jar --spring.profiles.active=test-zf -Xms128M -Xmx256M
12235 hk-pay.jar --spring.profiles.active=test -Xms128m -Xmx128m -agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
21069 intl-pay.jar --spring.profiles.active=test -Xms128M -Xmx256M
13902 converge-pay.jar --spring.profiles.active=test-zf -Xms256M -Xmx256M
jinfo(Configuration Info for Java)
实时的查看和调整虚拟机的参数。
jinfo pid 输出全部的参数和系统属性
jinfo -flag name pid 输出对应名称的参数
jinfo -flag [+|-]name pid 开启或者关闭对应名称的参数
jinfo -flag name=value pid 设定对应名称的参数
jinfo -flags pid 输出全部的参数
jinfo -sysprops pid 输出系统属性
jstat(JVM Statistics Monitoring Tool)
监控JVM各种运行状态信息的命令行工具。
[root@izm5e4dhkm7u54kfwhgz9wz logs]# jstat -options
-class 监视类装载、卸载数量、总空间以及类装载所耗费的时间
-compiler 输出JIT编译器编译过的方法和耗时等信息
-gc 监视Java堆状况,包括Eden区、survior区、old区、永久代等的容量、已用空间、gc时间合计等信息
-gccapacity 监视内容与-gc基本相同,但输出主要关注java堆各个区域使用到的最大、最小空间
-gccause 与-gcutil相同,但额外会输出导致上一次gc产生的原因
-gcmetacapacity 输出metaspace的最大和最小空间
-gcnew 监视新生代gc状况
-gcnewcapacity 监视内容与-gcnew基本相同,但输出主要关注j使用到的最大、最小空间
-gcold 监视老年代gc状况
-gcoldcapacity 监视内容与-gcold基本相同,但输出主要关注j使用到的最大、最小空间
-gcutil 监视内容与-gc基本相同,但输出主要关注java堆已使用空间占总空间的百分比
-printcompilation 输出已经被JIT编译器编译的方法
jstack(Stack Trace for Java)
生成JVM进程当前时刻的线程的调用堆栈,可以用来定位线程间死锁、锁等待、等待外部资源等。
jstack [option] pid
-F 当正常jstack正常的请求不被响应时,强制输出线程堆栈
-l 输出锁的附加信息
-m 如果调用本地方法,可以输出C/C++堆栈
输出并保存:
[root@izm5e4dhkm7u54kfwhgz9wz logs]# jstack 12235 > jstack.log
jmap(Memory Map for Java)
生成堆转储快照dump文件,除了这种方式还可以通过 -XX:HeapDumpOnOutOfMemoryError参数,可以在虚拟机发生OOM的时候自动生成堆的dump文件。jmap除了生成堆的dump文件 也可以查看查看堆的信息,查询finalize执行队列等。
[root@izm5e4dhkm7u54kfwhgz9wz logs]# jmap -dump:format=b,file=heap201906121146.bin 12235
Dumping heap to /opt/converge-pay/logs/heap201906121146.bin ...
Heap dump file created
-dump:[live,]format=b,file=<filename> 使用hprof二进制形式,输出jvm的heap内容到文件=. live子选项是可选的,假如指定live选项,那么只输出活的对象到文件.
-finalizerinfo 打印正等候回收的对象的信息.
-heap 打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况.
-histo[:live] 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量.
-permstat 打印classload和jvm heap长久层的信息. 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来.
-F 强迫.在pid没有相应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效.
-h | -help 打印辅助信息
-J 传递参数给jmap启动的jvm.
服务环境
CPU
top
主要关注cpu的load,以及比較耗cpu的进程。 因为如今server都是虚拟机,还要关注st(st 的全称是 Steal Time 。是分配给执行在其他虚拟机上的任务的实际 CPU 时间) 请参考另一篇文章:top命令详解
内存
free
[root@izm5e4dhkm7u54kfwhgz9wz ~]# free -m -c10 -s1
total used free shared buff/cache available
Mem: 3790 1994 153 1209 1642 135
Swap: 0 0 0
-m:以MB为单位显示。其它的有-k -g -b
-s: 间隔多少秒持续观察内存使用状况
-c:观察多少次
vmstat
[root@izm5e4dhkm7u54kfwhgz9wz ~]# vmstat 1 10
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
5 0 0 145864 5780 1680672 0 0 23 14 0 0 1 1 97 0 0
0 0 0 145660 5788 1680700 0 0 0 72 7158 11437 4 16 80 0 0
1表示每隔1s输出一次,10 表示输出10次
两个參数须要关注
r: 执行队列中进程数量,这个值也能够推断是否须要添加CPU。(长期大于1)
b: 等待IO的进程数量。
IO
iostat
[root@izm5e4dhkm7u54kfwhgz9wz ~]# iostat -m 1 10
Linux 3.10.0-693.2.2.el7.x86_64 (izm5e4dhkm7u54kfwhgz9wz) 06/12/2019 _x86_64_ (2 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
1.46 0.00 1.13 0.08 0.00 97.33
Device: tps MB_read/s MB_wrtn/s MB_read MB_wrtn
vda 3.61 0.04 0.03 2140135 1302884
-m:某些使用block为单位的列强制使用MB为单位
1 10:数据显示每隔1秒刷新一次。共显示10次
网络
netstat
netstat -antp
-a (all)显示全部选项。默认不显示LISTEN相关
-t (tcp)仅显示tcp相关选项
-u (udp)仅显示udp相关选项
-n 拒绝显示别名,能显示数字的所有转化成数字。
-l 仅列出有在 Listen (监听) 的服服务状态
-p 显示建立相关链接的程序名
显示tcp各个状态数量:
[root@izm5e4dhkm7u54kfwhgz9wz ~]# netstat -ant |awk '{print $6}'|sort|uniq -c
26 CLOSE_WAIT
1 established)
75 ESTABLISHED
1 Foreign
25 LISTEN
1 SYN_SENT
14 TIME_WAIT
查看连接某服务port最多的的IP地址
[root@izm5e4dhkm7u54kfwhgz9wz ~]# netstat -nat | grep "127.0.0.1:8060" |awk '{print $5}'|awk -F: '{print $4}'|sort|uniq -c|sort -nr|head -10
6
面试题:
1、线上Java项目CPU突然飙到100%怎么排查?
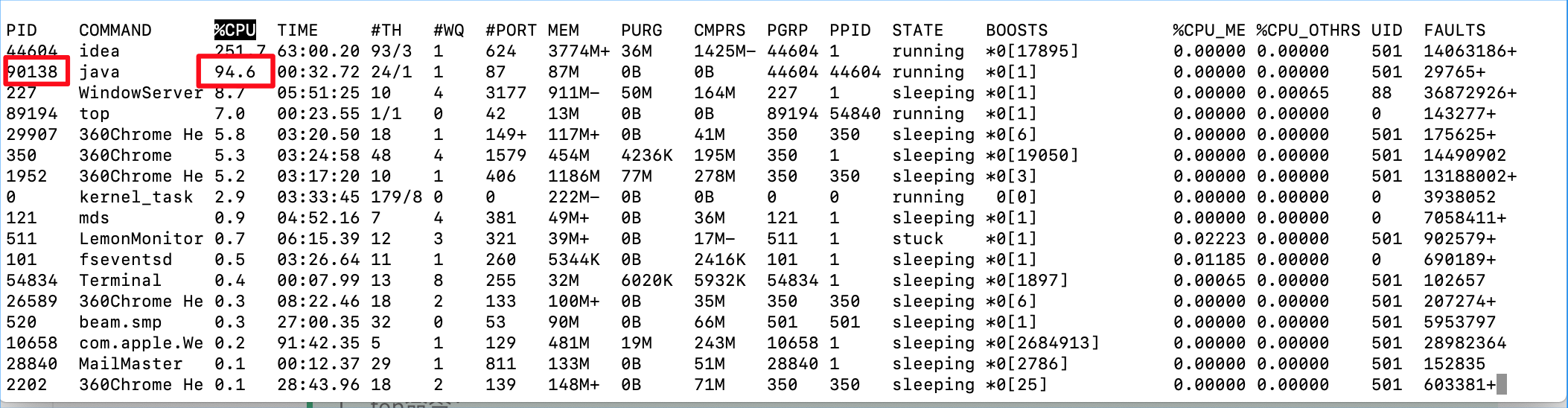
1、top命令:
2、进程号:pid: 90138
3、根据pid查线程:
top -Hp 90138
查出cpu使用较高的线程号:1700
4、将线程转换成16进制。
printf '%x' 1700
转换后的值:6a4
5、将进程放到一个文件去:
jstack 90138 > 90138.txt
6、查看生成的文件:
vi 90138.txt
搜索: /find 6a4
既可以发现其线程,既可找到业务代码:然后去排查代码问题。
2、线上java服务器内存飙升?
1、top(看mem最大的那个记下pid) ->shift +m(以内存排序)--> jmp -dump:format=b,file=heap.hprof (pid) 生成堆的转存文件 (heap.hprof文件) 从服务器上下载文件到本地。
2、通过eclipse memory analyzer工具(mat)打开heap.hprof-->看什么类引起的。